Face Detection and Recognition System 🔎
Date: 07.12.2020
Face detection systems are being used more and more frequently, I wanted to explore how it is working behind the scenes. My goal was to develop a system that reacts on images being emitted by webcams, processes the images (extract faces and recognize the persons behind them) and displays the information to the owner of the webcam. Face detection and recognition systems are used in law enforcement Interpol, in social media applications such as Instagram (it detect faces and the position of the eyes, nose etc to overlay the picture with the filter effects).
Basically, they find faces in an input image, and then try to classify the found faces and assign a label (= the person’s name) to it.
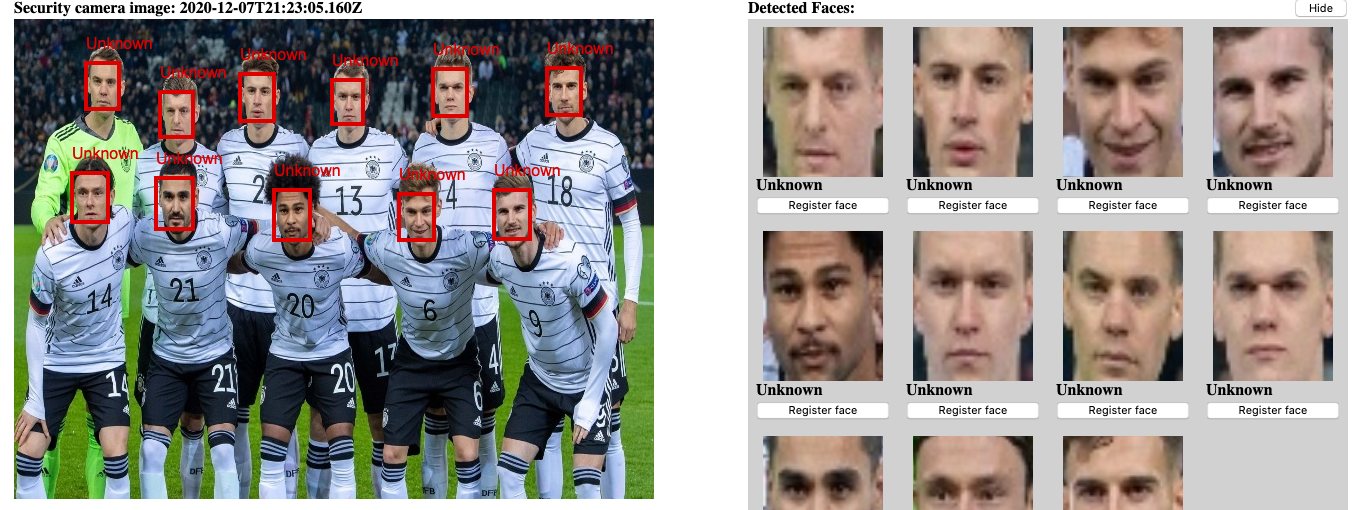
How does it work?
My system follows the same principle:
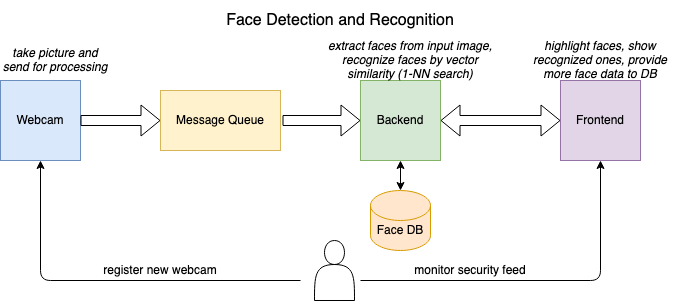
The input images are provided by a Python script that takes a picture from a webcam and sends it to the system via a message queue (RabbitMQ).
The message then is received by the backend system which detects faces in the image using a Multi-Task Cascaded CNN (MTCNN). In particular, I use an already pretrained model by the ipazc/mtcnn Python-library.
This library returns a list of detected faces to an input image together with detected facial landmarks (eye position, mouth, nose…).
These landmarks then are used to align the face:
Unaligned face:

Aligned face:

Alignment in our system consists of orienting the face and centering the eyes vertically.
The aligned faces then are fed into the feature extraction layers of a pretrained VGGFace model. This model has been trained on a dataset of faces of 20k people (see https://www.robots.ox.ac.uk/~vgg/data/vgg_face/) to classify faces to the label representing one person.
By stripping the last layer, we basically just use the face embedding the model has learned. As it should assign the same class to different face pictures of the same person, it should embedd faces of the same person close to each other in a vector space.
This approach follows the Word2Vec embedding for textual data. The idea is that words with a close semantic meaning are close to each other in terms of their vector representation.
For faces we now use the same approach: we vectorize faces in an input image and compare them to labeled faces in our database. Faces are compared using the Cosine Similarity:
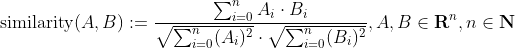
Then, we use the first Nearest-Neightbor in the set of all candidate faces and assign the label of this face to our face to classify.
The big advantage of using k-NN with a suitable similarity measure over using a deep-neural network such as VGGFace for also classifying the faces is that adding new labels to the dataset does not require retraining the model. As the vector representations for existing labels will remain the same and new class will form a new cluster in the vector space, we easily can xpand the system to recognize more people.
The disadvantage is that for every face recognitions the whole database needs to be evaluated.
For small datasets this is not an issue, but in case we have 1000s of images in the database this would increase the time to recognize a face.
There are techniques to avoid having to evaluate the whole database (e.g pivot-based metric indexing , approximations), which I have not implemented yet in the system, but can be a future extension.
Future extensions
- more efficient dataset handling
- improved user interface (adding new webcams)
- tracking people: link different camera images and keep track of people in a building
- notifications: mark dangerous people and get a notification if they are close to the camera
Thanks for following my journey to build a face detection and recognition system. ✌️