Traffic Sign Detection using an RCNN🚦
Date: 15.05.2021
In a previous project on Face Detection, I have used a library to detect faces in images. This library took away the heavy lifting required to find the faces. This time I wanted to implement the detection part on my own and I chose to build a detector for traffic signs. Traffic sign detection systems are becoming more and more mainstream in modern cars, supporting drivers in keeping speed limits and to make driving safer.
Detection system historically followed a sliding-window approach where the system would check each part of the image and try to classify it. In order to deal with different siyes of objects this process had to be repeated several times in order to detect the objects of interest. This means a lot of classification effort as there are a lot of potential places where an object could be placed.
These limitations prevented real-time applications of detection systems.
In 2014, Girshick et al. proposed a faster approach replacing the sliding window generator for regions of interest by a selective search based one. This approach reduced the number of candidates to consider dramatically and speeded up the process. They named their aproach RCNN.
Even though this approach is already faster than the previous sliding window approach it still suffers from having to classify several hundreds of candidates. This is why even faster approaches such as Fast-RCNN or YOLO have been invented. In these approaches a single neural network detects and classifies objects. A blog post explaining the differences can be found here.
As my NVIDIA Jetson Nano 2GB was not able to run a YOLO v3 implementation due to storage constraints, I decided to follow the RCNN approach to build a traffic sign detection system. It required training a multiclass classifier based on an CNN to assign classes (either the traffic sign or background) to each candidate only which could be easily done, as there already exists a dataset for traffic sign recognition: https://www.kaggle.com/meowmeowmeowmeowmeow/gtsrb-german-traffic-sign.
The dataset consists of images of more than 40 different traffic signs. However for my approach it was lacking a background class. As not every candidate will contain traffic signs (due to the nature of the selective search algorithm used, which segments images based on the pixel colors to identify objects, see Blog post on Selective Search), the classifier requires some negative examples to not be too eager to classify each candidate as a traffic sign.
However, the data set suffers from severe class imbalances:
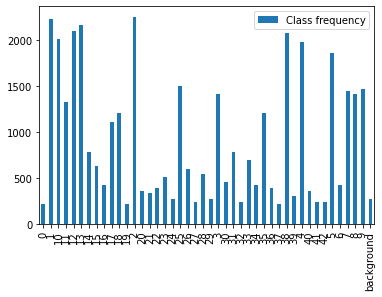
The range of images per class ranges from ~250 to 2300. This needs to be kept in mind when training the classifier.
To deal with this imbalance I have used several data augmentation steps to train the CNN:
- random rotations (up to 15°)
- random cropping, to shift the center of the images
I could not use random flips of images, as these would change the images (e.g a left-pointing arrow would suddenly become a right-pointing one, but they do not represent the same class of images)
![]()
![]()
During training the model achieved ~85% accuracy (same on the validation set)
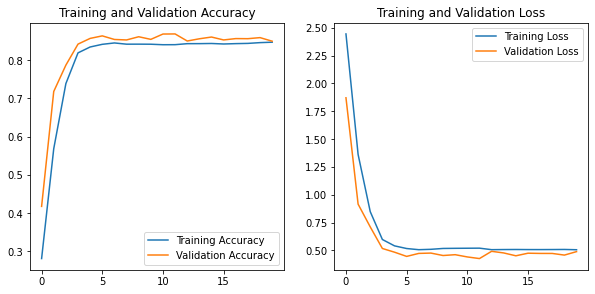
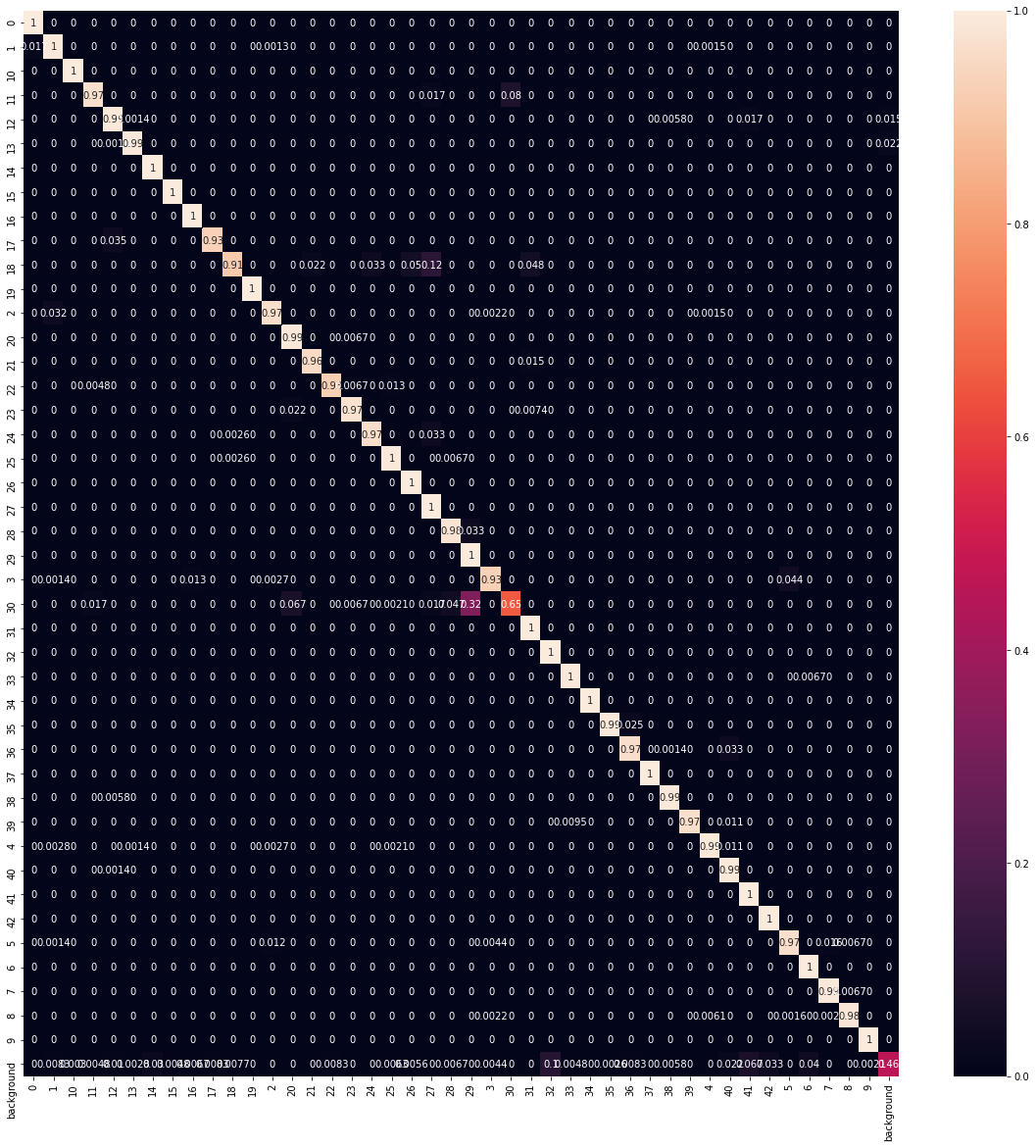
On the test set, the model achieved 97% accuracy with an F1 score of 0.97, meaning it has a decent recall and precision. However when looking at the confusion matrix, it becomes eminent that the model struggles detecting background (less than 50% correct - likely due to the low prepresentation and large variety in the background class), and confuses class 30 with class 29 (two warning signs, one for cyclists the other for snow).
Based on the classifier, I continued implementing the RCNN to detect traffic signs. Using Open CVs Selective Search algorithm and a non-maximum-suppression algorithm to aggregate overlapping candidates representing the same class.
At the end I had a system that detects traffic signs in images:

It is still a bit rough and requires more fine tuning: e.g the confidence threshold for the classifier, the overlap ratio for the non-maximum-suppression, but it works surprisingly well. The system correctly identified the stop sign and the arrow pointing forward. It also captured enough information during training the detect two different types of the arrow pointingforward: a round sign and a rectangular one.
However this system is far from being usable in real-time: the total time needed on my NVIDIA Jetson Nano 2GB, was 87 second. 96% of that time was spent on the selective search for candidate regions.
As stated before other approaches such as Faster RCNN or YOLO v3 avoid the candidate generation step, but I decided to stick with the simpler approach as it was easier to train the classifier. There are a few option to try to improve the runtime, e.g resizing the input image, but they usually come at cost of detection quality.
The Jupyter notebook of the project can be found on Github: Traffic Sign Detection via RCNN, thank you for following me on my journey to build an object detection system for traffic signs. 🤓